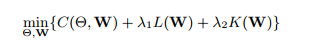Visual Relationship Detection with Languages Priors
Abstract
This passage propose a model that uses the insight that combines objects and predicates to train visual models for models and predicates individually and later combines them together. Additionally, it localizes the objects in the predicated relationships as bounding boxes in the image.
Introduction
While we poses similar challenges as object detection, one critical difference is that the size of semantic space of relationships is much larger. A fundamental challenge in visual relationship detection is learning from very few examples
Visual Phrases :using 13 common relationships, needs to train O(N^2K) . person-jumping-off-bikesis rare while person and bikes are usual. So the authors propose a visual appearance module that fuses objects and predicates together to jointly predicate, only need O(N + K)
Word vector embeddings naturally similar objects in linking their relationships (e.g., “person riding a horse” and “person riding a elephant”). There is a language module that uses cast pre-trained word vectors to cast relationships into a vector space where similar relationships are optimized to be close to each other.(can even enable zero-shot learning)
Related
object co-occurrence statistics
spatial relationships (used to improve segmentation: “above”,”below”,”inside”,”around”)
human-object interaction
all previous work has attempted to detect only a handful of visual relationships and do not scale. Module in this passage is able to scale and detect millions relationships,including unseen ones.
Visual Relationship Detection
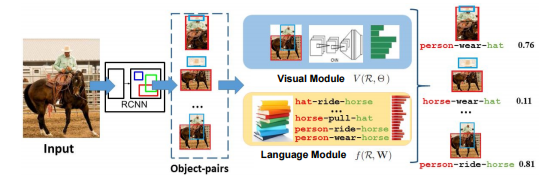
The input is a fully supervised set of images with relationships annotations where the objects are localized as bounding boxes and labeled as <*objects1-predicate-object2>.
Training Approach
Visual Appearance Module
- A CNN to classify N = 100 objects
- A second CNN to classify K =70 predicates using the union of the bounding boxes of two participation objects in that relationship.
R(i,k,j) denotes relationships, i and j are the object classes with bounding boxes O1, O2
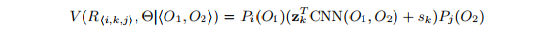
Language Module
Infer from similar relationships that occur more frequently by projecting relationships into an embedding space where similar relationships are closer
Projection Function: word2vector() denotes a word to its 300 dim.vector, wkis 600 dim. Each row if W represents one if K predicates
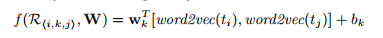
- Training Project Function: making similar closer and different further, that is a heuristic where the distance is proportional to word2vec distance
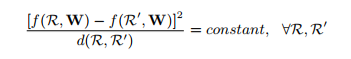 d(R,R’) is the sum of the cosine distances. So we randomly sample pairs of relationship and minimize their variance
d(R,R’) is the sum of the cosine distances. So we randomly sample pairs of relationship and minimize their variance 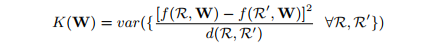
- Likelihood of a Relationship : The output should indicate the visual relationship.
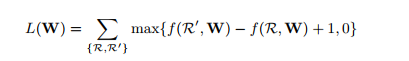
Objective function
Ranking loss function
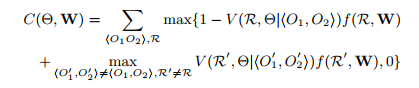
As a result, we need to minimize this function. So our final objective function as: