Visual Translation Embedding Network for Visual Relation Detection
Abstract
“Person ride bike “ offers a comprehensive understanding of an image, connecting CV and NLP. Due to the challenging complexity of finding the relation, this passage offers Visual Translation Embedding network(VTranse: subject+predicate=object) for visual relation detection.(competitive to Lu’s multi-modal model with language priors–[])
Note:
- a novel feature extraction layer that enables object-relation knowledge transfer in a fully-convolutional fashion that supports training and inference in a single forward/backward pass.
Background
This are lots of efforts that connecting computer vision and natural language: visual caption and question answering (mostly connects CNN and RNN,operimized on specialized datasets for specific tasks : image caption or image QA….), falling short in understanding relationships
Introduction to VTransE
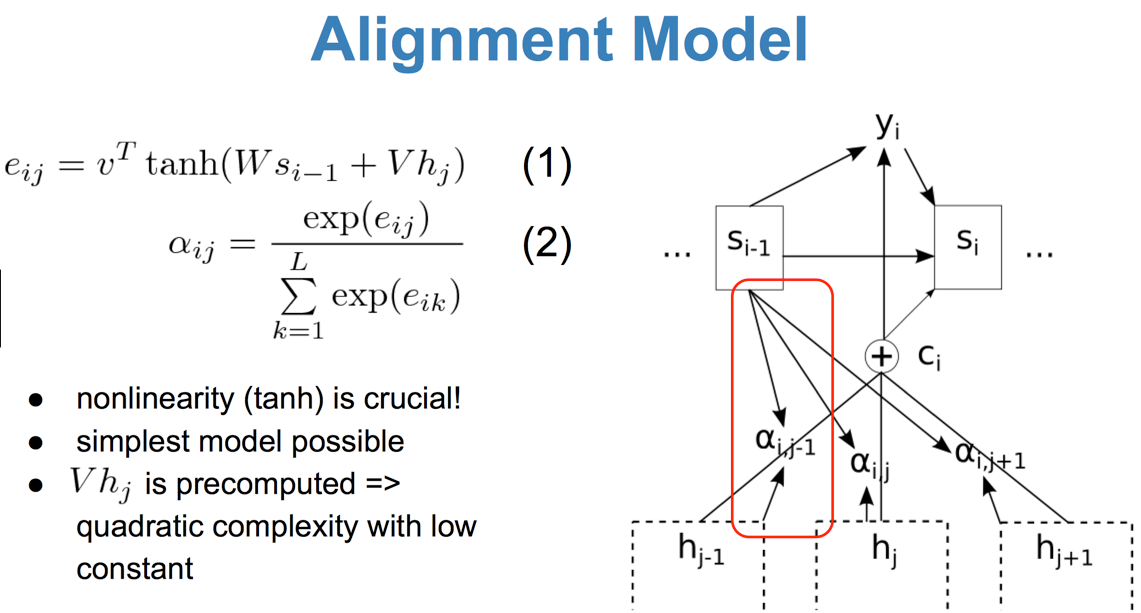
Translation Embedding
Assume we have N objects and R relation
the fundamental challenge is O(N^2R).A common solution: to learn separate models for objects and predicates: O(N+R)(even more challenge ,compare “ride bike“ to “ride elephant“). TransE : representing large-scale in lower dimensional space, the relation triplet can be interpreted as a vector translation : person + ride = bike , only need to learn the ride translation vector in the relation space.
Knowledge Transfer in Relation
For example, person and bike detection serves as the context for ride prediction, Specifically, we propose a novel feature extraction layer that extracts three types of object features used in VTransE: classme,locations and RoI visual features. It uses bilinear feature interpolation[15,20] instead of RoI pooling for differentiable coordinates
Summary:
VTransE, a convolutional network that detects objects and relations, first end-to-end relation detection
A novel visual relation detection learning model for VTansE that incorporates translation embedding and knowledge transfer
VTransE outperforms several strong baselines
more >>