
Visual Translation Embedding Network for Visual Relation Detection
Abstract
“Person ride bike “ offers a comprehensive understanding of an image, connecting CV and NLP. Due to the challenging complexity of finding the relation, this passage offers Visual Translation Embedding network(VTranse: subject+predicate=object) for visual relation detection.(competitive to Lu’s multi-modal model with language priors–[])
Note:
- a novel feature extraction layer that enables object-relation knowledge transfer in a fully-convolutional fashion that supports training and inference in a single forward/backward pass.
Background
This are lots of efforts that connecting computer vision and natural language: visual caption and question answering (mostly connects CNN and RNN,operimized on specialized datasets for specific tasks : image caption or image QA….), falling short in understanding relationships
Introduction to VTransE
Translation Embedding
Assume we have N objects and R relation
the fundamental challenge is O(N^2R).A common solution: to learn separate models for objects and predicates: O(N+R)(even more challenge ,compare “ride bike“ to “ride elephant“). TransE : representing large-scale in lower dimensional space, the relation triplet can be interpreted as a vector translation : person + ride = bike , only need to learn the ride translation vector in the relation space.
Knowledge Transfer in Relation
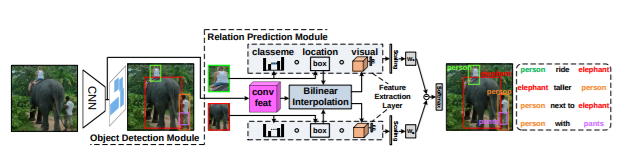
For example, person and bike detection serves as the context for ride prediction, Specifically, we propose a novel feature extraction layer that extracts three types of object features used in VTransE: classme,locations and RoI visual features. It uses bilinear feature interpolation[15,20] instead of RoI pooling for differentiable coordinates
Summary:
VTransE, a convolutional network that detects objects and relations, first end-to-end relation detection
A novel visual relation detection learning model for VTansE that incorporates translation embedding and knowledge transfer
VTransE outperforms several strong baselines
Related Work:
Visual Relation Detection:Divide relation model into joint and separate model. We use separate model , mapping information into low-dimensional space. There are works that exploit language priors to boost relation detection.
Object Detection: We use Faster-RCNN, while applying bilinear interpolation instead of the non-smooth RoI polling ( making the learning be achieved in a single forward/backward pass)
Into VTransE Network
Visual Translation Embedding
Given subject - predicate - object in low-dimensional vectors s,p,o. When relation holds, s + p app = o. The first thing we need to do is to transfer TransE in visual domain, which is consistent to recent works in visual semantic embeddings.
In TransE , use large-margin metric learning loss function for relation: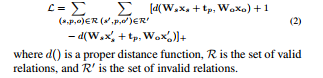
e.g, AlanTuring-bornIn-London,visual relations are volatile to specific visual examples.(e.g, car-taller-people). We only rewards the deterministically accurate predicates(not the agnostic),using softmax.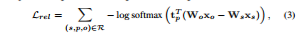
In fact, softmax is a rotational approximation model for basic wx+ b*, (using weight decay?), (**If the annotation is complete, VTransE works with Eq.(1) and Eq.(2) interchangeably).
The final score is the sum of object detection score and predicate predication score Eq.(2):
Ss,p,o = Ss + Sp + S o
Feature Extraction
There are three types of features that characterize the multiples facets of objects in relations .M = N + D +5
Classeme: (N+1)-d vector of object (*i.e., N classes and 1 background). Sometimes a useful prior for rejecting relation like “cat-ride-person”
location: 4-d vector (tx,ty,tw,th), a bounding box parameterization , (tx,ty) specifies a scale-invariant translation and (tw,th) specifies the log-space height/width shift relative to its counterpart.
Visual Feature:D-d vector transformation from a conv feature of the shape X x Y x C(the same size of RoI pooling in Faster-RCNN), the features are bilinearly interpolated from the last conv-feature map, to achieve end-to-end training.
Details
training image: subject-predicate-object each item is annotated with a bounding box
Object Detection Network: starts from the Faster-RCNN with VGG-16 architecture,256 region proposal boxes generated by RPN , each is positive if IoU > 0.7. The positive proposals are fed into the classification layer, outputs an (N + 1) class probabilities and N bounding box estimations. The use NMS for every class whose IoU > 0.4. (Why NMS?: 1) need a specific object class for each region. 2) down-sample the objects for a reasonable number). Resulting in 15-20 detections per image on average.
Bilinear Interpolation: use the las conv feature map F of the shape W‘ H‘ C(C = 512,the number of channels , W‘ = W/16) by removing the final pooling layer. When back-propagated to the object detection network , the function is not smooth function since it requires discrete coordinate gradients. So we replace it with Bilinear Interpolation.Input: feature map F and the bounding box. Outout : feature V with the size X Y C
Optimization: Training by stochastic gradient descent with momentum, follows “image-centric?“ strategy. Loss = Lossobj+ Lossrel,
Pre-train Faster-RCNN on the objects in relation datasets to init the network and init VTransE with Gaussian component. (Can always plug-in faster object object detection networks such as YOLO and SSD)
