
Relation Network
With the emergence of some Deep neural networks(DNN), such as ResNet, the ImageNet challenge is not so difficult as before. As a result, since recognition tasks are going to be solved, we are going to deal with a high-level question, including visual understanding.
Visual Question Answering has attracted much attention these years. Besides, visual relation is also going to be an issue we should consider.
Visual Question Answering
Although we have seen lots of models on VQA, such as LSTM, attention-based model and stacked LSTM in terms of . In fact, Visual Question Answeing is still kinda classification, far from true reasoning. So, people guess there might be some constriants, the first problem is inside the network, points to the conv nets these days still can’t “think”, the second problem is it is hard to debug if we works directly on natural images.
The network
Towards this question, some peole have done something, such as explicitly adding reasoning or memory module into the network
- Neural Module Networks :This paper comes up with a module that can let the network doing compositional reasoning.
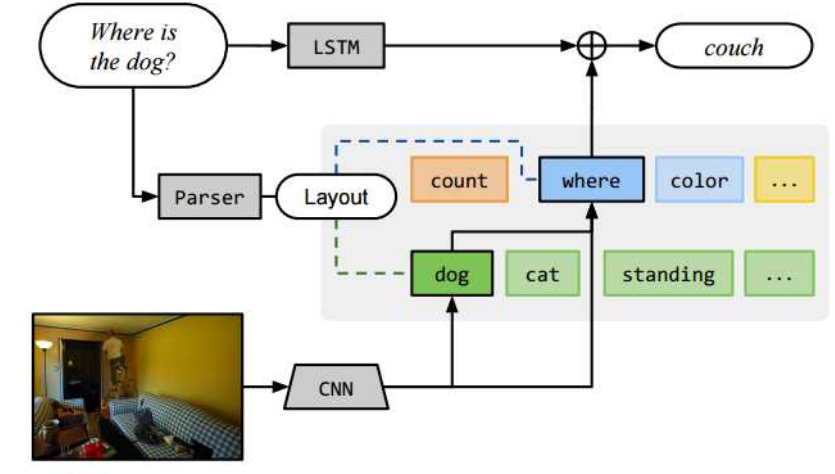
Dataset

Some researchers start to composite image using graphics, aimed at establish new VQA dataset. This may help to analysis model’s action and performance.
CLEVR: 100000 images and 1000000 pairs of question and answer. All of the images aare rendered by Blender. The basic attributes are three object shapes(cube, sphere, cyclinder), two absolute sizes(small and large), two materials(shiny,matte), four relationships(left,right,behind,in front). And also, there are 90 questions, represented both in natural language and as a “so-called” functional program. that can sample new questions.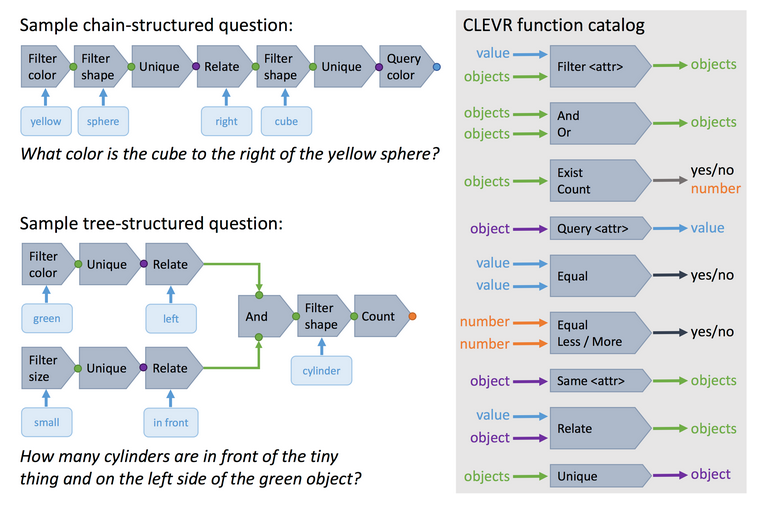
Later..
Those authors have another paper published at ICCV 2017:
Also, those two modules can be trained seperatly sicne the question generation program can be set.
Generally speaking,the training process is quite strange since we are given the question generation programs,”uses additional supervisory signals on the functional programs used to generate the CLEVR questions”. Anyway, this provides some clues about the up-coming Relation Network.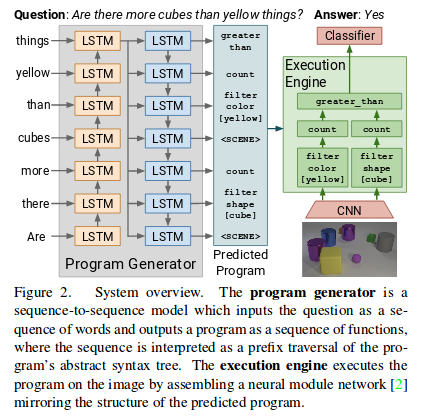
Visual Relation Network
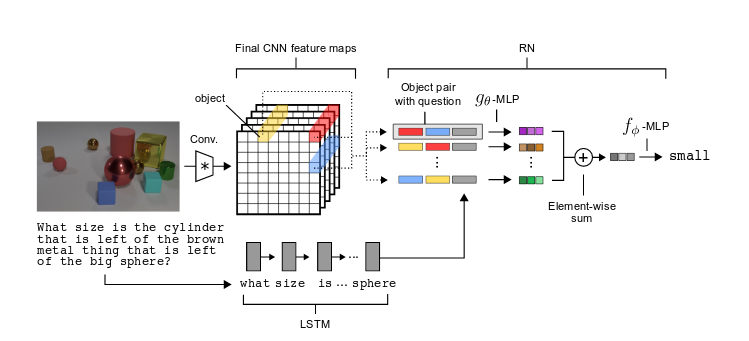
The model is quite simple here: let LSTM encode the question and then pair with deep feature with spatial cell. Finally, add FC layers to softmax classify them to some specific words.
The only model can be like: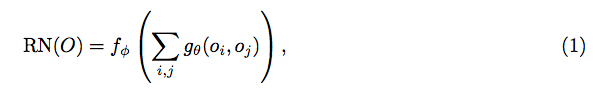
Since all the relations inside are pairwise object’s relation, such as mouse and cat, that’s what the model relies on.
This model can let the network implicitly learn the functional programs used to generate the CLEVR questions.
Future work
- Understanding and Visual Relation Detection inside relation network
- Extend to triplet relations or real work datasets