
As the last post said, Professor Garrison wanted us to work on some medical dataset, the camelyon16 was the one we should work on, which is a quite large and difficult one. Somehow, we switch the database to this one ChestX-ray8, a new significant work in CVPR 2017.
About the dataset
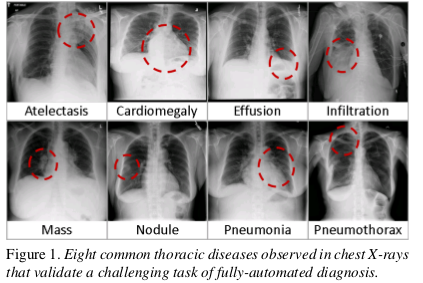
This is a new chest X-ray database, whihc comprises 108948 frontal-view X-ray image of 32717 unique patients with the text-mined eight disease image labels This paper also demonstrates that these diseases can be detected and even spatially-located via a unified Weakly-Supervised multi-label image classfication and diseases Localization framework
Intro
Rapid and tremendous progress has been evidenced in lots of CV problems, compared to previous shallow methodologies built upon hand-crafted image features. However, some evaluation between using PASCAL VOC and MS COCO demonstrate that there is still some room for performance improments. Similarly, deep learning yields rises in performance in the medical image analysis. Recent work :………….. The main limitation is that all proposed methods are evaluated on some small-to-middle scale problem(several hundreds images). It’s unclear how well the deep learning methodologies will perform when scale up to tens of thousands of patients
What’s special about the database
Some big databases need a lot of human efforts, such as AMT.The author exploit to mine the pre-image Common thoracic pathology labels from the image-attached chest X-ray radiological reports using NLP techniques. Though the pathological region can have different size, they all all small compared to full image. As shown in the pic below.
The author formulates a weakly-supervised multi-label image classification and disease localization framework to address the bounding box.
Related work
The former largest public dataset is OpenI that contains 3955 radiology reports and 7470 associated chest x-rays from the hospital.
Labeing each pictures with NLP techniques
I am not quite understand this part now, so we will discuss about it next time. :-D Don’t forget !!!
Processing Chest X-ray Images
Then typical X-ray image dimensions of 3000 X 2000 pixels. In ChestX-ray8, X-rays images are directly extracted from the DICOM file and resized 1024 x 1024 bitmap images without significantly losing details, compared to 512 x 512 in OpenI
Bounding Box
A small number of the database are provided with hand labeled bounding boxes, which can be used as the ground truth to evaluate the disease localization perform, which can be adopted for one/low-shot learning setup.
About the network(Most important!!!)
As the main application of ChestX-ray8 dataset, the author present a unified weakly-supervised multi-label image classification and pathology localization framework, which can detect the presence of multiple pathologies and subsequently generate bounding boxes around the corresponding pathologies. In details, he tailors DCNN architectures for weakly-supervised object localization, by considering large image capacity, various CNN losses and different polling strategies.
Unified DCNN Framework
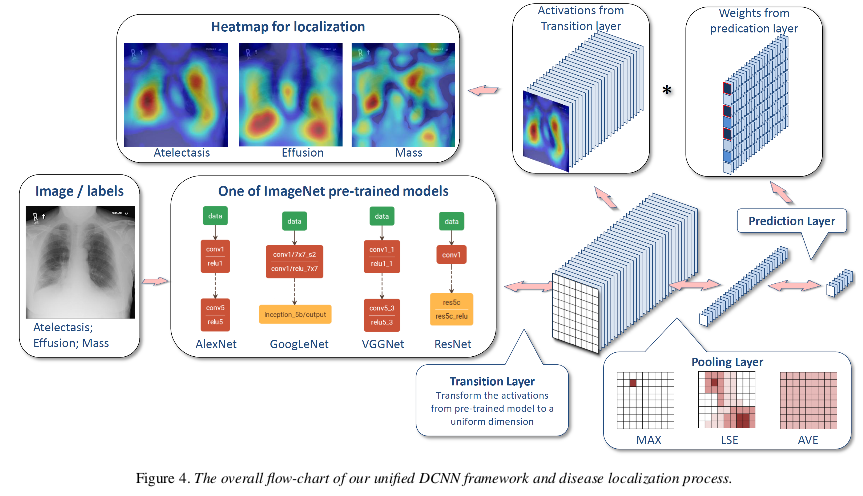
They perform the network surgery on the pre-trained models(Using ImageNet), e.g. AlexNet, GoogleNet, VGGNet-16, ResNet-50, by leaving out the fully connected layers and the final classification layers. Instead, insert a transition layer, a global pooling layer, a prediction layer and a loss layer in the end. (a combination of deep activations from transition layer(a set of spatial image features)and the weights of the prediction inner-product layer can help us to find the localization of disease)
Transition Layer
Due to the large variety of pre-trained DCNN architectures, transform the activation from previous layer and generates a uniform the activations from previous layer into S x S x D. It helps pass down the weights from ptr-trained (e.g. 1024 for GoogleNet and 2048 for ResNet) Use convolution???
multi-label classification Loss Layer
experience 3 standard loss functions for the regression task instead of softmax loss for traditional multi-class classification model i.e. Hinge Loss, Euclidean Loss and Cross Entropy Loss. However, due to the “one-hot” like labels are very sparse . Therefore, introduce a balancing factor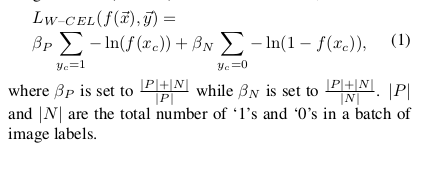
Global Pooling Layer and prediction Layer
the global pooling and the predication layer are designed not only to be
part of the DCNN for classification but also to generate the likelihood map of pathologies, namely a heatmap.
Global Pooling Layer
The pooling layer choose what information to be passed down, tried LSE, max, average pooling. Since the LSE function suffers from overflow/underflow problems, Use
Bounding-Box Generation:
Due to the simplicity of intensity distributions in these resulting heatmaps, applying an ad-hoc thresholding based B-Box generation method for this task is
found to be sufficient